on
딥러닝 - ViT (Vision Transformer) 설치 및 Fine Tuning
딥러닝 - 지난 글
목차
ViT (Vision Transformer)
ViT(Vision Transformer)은 기존의 Convolutional Neural Network (CNN)을 대체하고자 하는 이미지 인식을 위한 딥러닝 아키텍처입니다. ViT는 Transformer 아키텍처를 비전 분야에 적용하여 이미지 처리를 수행하는 모델입니다.
기존의 CNN은 이미지의 공간적인 구조를 활용하여 이미지 특징을 추출하는 데 강점을 가지고 있었습니다. 그러나 CNN은 이미지의 전역 정보와 픽셀 간의 상호작용을 완전히 모델링하기는 어렵습니다. 이에 반해, Transformer는 자연어 처리 분야에서 탁월한 성과를 거두었으며, 시퀀스 데이터의 상호작용을 모델링하는 데 강점을 가지고 있습니다.
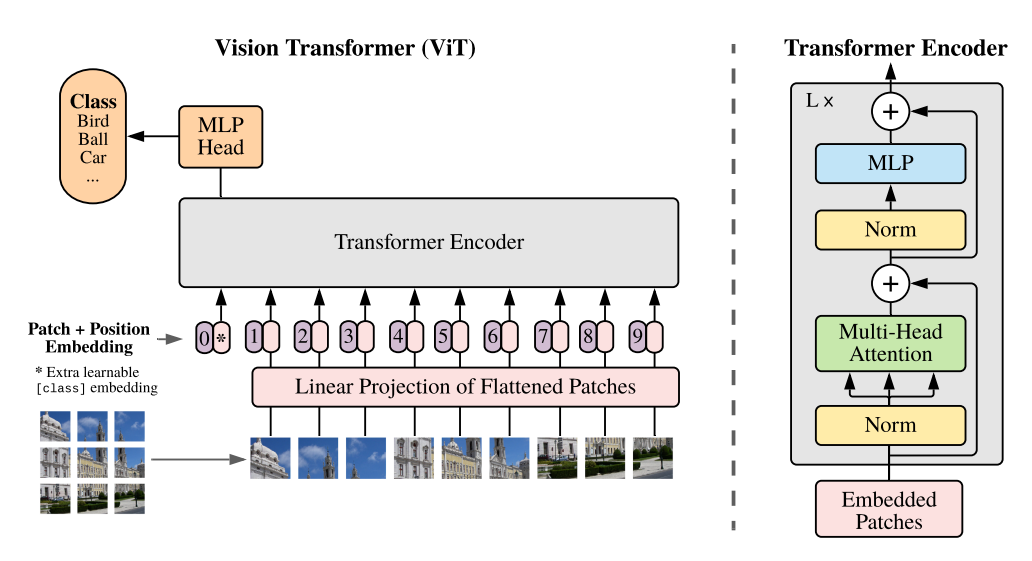
ViT는 이미지를 작은 패치로 분할하고, 이를 픽셀 수준이 아닌 토큰 단위로 처리하여 Transformer의 입력으로 사용합니다. 패치들은 Flatten된 후 임베딩 과정을 거쳐 토큰 시퀀스로 변환됩니다. 이렇게 얻어진 토큰 시퀀스는 Transformer의 인코더로 전달되어 이미지에 대한 표현을 학습합니다.
ViT의 핵심은 패치 간의 상호작용을 모델링하는 Transformer의 self-attention 메커니즘입니다. Self-attention은 입력 시퀀스 내의 모든 위치 간의 관계를 동적으로 계산하여 중요한 정보를 집중적으로 수집하는 능력을 가지고 있습니다. 이를 통해 ViT는 이미지 내의 패치 간 상호작용을 고려하여 이미지에 대한 컨텍스트를 파악할 수 있습니다.
ViT는 비전 분야에서의 이미지 분류, 객체 감지, 이미지 생성, 시맨틱 분할 등 다양한 작업에 적용될 수 있습니다. 특히, 대규모 데이터셋과 충분한 계산 리소스가 주어진 경우, ViT는 경쟁력 있는 성능을 발휘할 수 있습니다.
ViT는 비전 분야에서 CNN과 Transformer를 결합하여 이미지 처리를 수행하는 혁신적인 아키텍처입니다. 이를 통해 이미지 인식의 전역 정보와 상호작용을 모델링하고, 다양한 비전 기반 작업에서 우수한 결과를 얻을 수 있습니다.
CLIP (Contrastive Language-Image Pretraining)
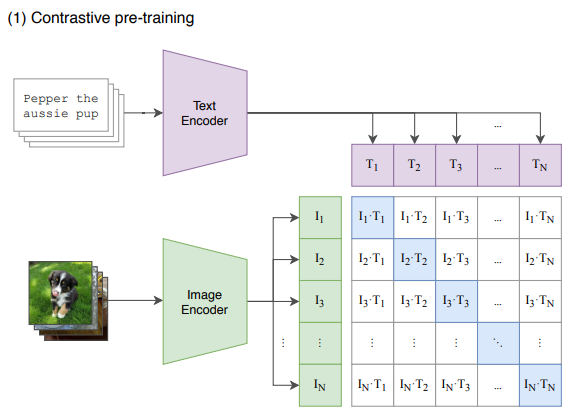
CLIP (Contrastive Language-Image Pretraining)는 OpenAI에서 개발한 비지도 학습 기반의 다목적 모델 프로젝트입니다. CLIP 프로젝트는 이미지와 텍스트를 함께 이해할 수 있는 모델을 구축하고자 합니다. 기존의 비전과 언어를 분리하여 처리하는 방식과는 달리, CLIP는 비전과 언어를 통합하여 모델을 훈련시킵니다.
CLIP의 주요 아이디어는 “텍스트와 이미지의 유사성을 학습하여 텍스트로 이미지를 설명하고, 이미지로부터 텍스트를 생성할 수 있다”는 것입니다. 이를 위해 CLIP는 대규모의 이미지 데이터와 텍스트 데이터를 사용하여 사전 훈련을 수행합니다. 텍스트 데이터는 웹 문서, 캡션, 설명 등 다양한 소스에서 수집됩니다. 그런 다음, 모델은 이미지와 텍스트 쌍 간의 상호 작용을 학습하여 이미지와 텍스트의 유사성을 파악하는 방법을 스스로 학습합니다.
CLIP는 Vision Transformer (ViT) 아키텍처를 기반으로 하며, ViT는 이미지를 작은 패치로 분할하고 이를 Transformer의 입력으로 사용하여 비전 데이터에 대한 효과적인 표현을 학습합니다. CLIP는 이러한 ViT 아키텍처를 텍스트 데이터와 함께 학습하여, 이미지와 텍스트 간의 공유된 표현을 생성합니다.
CLIP 프로젝트는 다양한 응용 분야에서 활용될 수 있습니다. 예를 들어, 이미지 분류, 객체 감지, 이미지 검색, 이미지 생성, 이미지 캡셔닝 등의 비전 기반 작업에서 CLIP 모델을 사용할 수 있습니다. 또한, 이미지와 텍스트 간의 상호 작용을 통해 텍스트에 대한 시각적 설명을 생성하거나, 이미지를 텍스트로 요약하는 작업에도 활용될 수 있습니다.
CLIP 프로젝트는 다양한 데이터셋과 사전 훈련된 모델을 제공하며, 개발자들은 이를 활용하여 자신의 데이터나 작업에 맞게 모델을 세부적으로 조정하고 훈련시킬 수 있습니다. CLIP는 이미지와 텍스트를 통합적으로 이해하고 다양한 시각적 추상화를 수행할 수 있는 강력한 기능을 제공하여 비전과 언어를 함께 다루는 다목적 모델 프로젝트로 주목받고 있습니다.
clip-vit-large-patch14
clip-vit-large-patch14는 OpenAI에서 개발한 Vision Transformer (ViT) 모델인 CLIP (Contrastive Language-Image Pretraining) 모델의 이미지 인식을 위한 변형된 버전입니다. CLIP 모델은 이미지와 텍스트를 함께 이해할 수 있는 다목적 비지도 학습 모델로, 비전과 언어를 통합하여 훈련됩니다.
CLIP 모델은 비지도 학습을 위해 대규모 데이터셋인 인터넷 이미지와 텍스트 데이터를 사용하여 사전 훈련되며, 사전 훈련된 모델은 다양한 비전 및 언어 기반 작업에 활용할 수 있습니다. CLIP는 이미지와 텍스트의 상호 작용을 모델링하고, 이미지와 텍스트의 유사성을 측정하기 위한 임베딩을 학습합니다.
clip-vit-large-patch14 모델은 ViT(Vision Transformer) 아키텍처를 기반으로 합니다. ViT는 기존의 Convolutional Neural Network (CNN)을 사용하는 이미지 분류 모델과는 다르게, Transformer 아키텍처를 이미지 분류에 적용한 모델입니다. ViT는 이미지를 작은 패치로 분할하고, 이를 픽셀 수준이 아닌 토큰 단위로 처리하여 비전 데이터에 대한 효과적인 표현을 학습합니다.
clip-vit-large-patch14 모델은 ViT의 큰 버전으로, 큰 크기의 입력 이미지에 대해 높은 수준의 시각적 추상화를 수행할 수 있습니다. 이 모델은 대규모 비전 데이터셋을 사용하여 사전 훈련되었으며, 이미지와 텍스트 간의 유사성을 학습하여 다양한 이미지 분류 및 비전 기반 작업에 사용할 수 있습니다.
clip-vit-large-patch14 모델은 CLIP 프로젝트의 일환으로 제공되며, 이미지 분류, 검색, 생성 등 다양한 비전 및 언어 기반 작업에 활용될 수 있습니다. 이 모델은 이미지와 텍스트를 통합적으로 이해하고 다양한 시각적 추상화를 수행할 수 있는 강력한 기능을 제공합니다.
ViT Fine Tuning
라이브러리 및 모듈 임포트
random: 랜덤 모듈에서 random 함수를 임포트합니다.numpy: 수치 연산을 위한 넘파이 라이브러리를 임포트합니다.pandas: 데이터 조작 및 분석을 위한 판다스 라이브러리를 임포트합니다.torch: 파이토치 라이브러리를 임포트합니다.torchvision: 컴퓨터 비전 작업을 위한 토치비전 라이브러리를 임포트합니다.transformers: 트랜스포머 모델과 훈련을 위한 라이브러리를 임포트합니다.sklearn.metrics: 사이킷런의 메트릭 모듈에서 평가 메트릭을 임포트합니다.matplotlib.pyplot: 시각화를 위한 맷플롯립 라이브러리의 플롯 모듈을 임포트합니다.
from random import random
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, random_split
from torchvision import datasets
from torchvision.transforms import (CenterCrop, Compose, Normalize,
RandomHorizontalFlip, RandomResizedCrop,
Resize, ToTensor, RandomApply, ColorJitter)
from transformers import ViTImageProcessor
from torch.utils.data import DataLoader
import torch
from transformers import TrainingArguments, Trainer
from sklearn.metrics import accuracy_score
from torch.utils.tensorboard import SummaryWriter
from transformers.integrations import TeansorBoardCallback
import matplotlib.pyplot as plt
랜덤 시드 설정
random_seed변수를 42로 설정하여 재현성을 위한 랜덤 시드를 설정합니다.torch.manual_seed함수를 사용하여 파이토치의 랜덤 시드를 설정합니다.
random_seed = 42
torch.manual_seed(random_seed)
커스텀 데이터 정의
- 학습 데이터와 테스트 데이터를
pd.read_csv함수를 사용하여 데이터프레임으로 로드합니다. - 학습 데이터의 클래스 레이블을
labels변수에 저장합니다. -
모델 학습을 위한 학습 데이터셋과 검증 데이터셋으로 데이터를 분할합니다.
torch.utils.data.Dataset클래스를 상속하는 CustomDataset 클래스를 정의합니다.CustomDataset클래스는 이미지 데이터와 레이블을 가지고 있으며, 데이터 변환 기능을 포함합니다.__getitem__메서드에서 데이터와 레이블을 반환하고, 필요에 따라 변환을 적용합니다.-
__len__메서드에서 데이터셋의 총 샘플 수를 반환합니다. CustomTestDataset클래스를 정의하여 테스트 데이터셋을 로드합니다.CustomTestDataset클래스는 이미지 데이터와 임의의 레이블을 가지고 있으며, 데이터 변환 기능을 포함합니다.
train_df = pd.read_csv('train_data_.csv') # 학습 이미지 및 레이블이 정리된 테이블
test_df = pd.read_csv('test_data.csv')
labels = train_df['Title'].unique() # 레이블
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
image_datasets = datasets.ImageFolder(root='./train(학습 이미지 폴더)')
id2label = {i: label for i, label in enumerate(image_datasets.classes)}
label2id = {v: k for k, v in id2label.items()}
train_dataset, valid_dataset = random_split(image_datasets, [0.8, 0.2])
class CustomDataset(Dataset):
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
self.features = {'label': labels}
def __getitem__(self, index):
img, label = self.dataset[index]
if self.transform:
img = self.transform(img)
return {'img': img, 'label': label, 'pixel_values': img}
def __len__(self):
return len(self.dataset)
class CustomTestDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.images = os.listdir(root)
self.labels = [0] * len(self.images) # Assign arbitrary labels
def __getitem__(self, index):
image_name = self.images[index]
image_path = os.path.join(self.root, image_name)
image = Image.open(image_path).convert("RGB")
if self.transform:
image = self.transform(image)
return {"img": image, "label": self.labels[index], "pixel_values": image}
def __len__(self):
return len(self.images)
데이터 변환 및 데이터로더 설정
- 이미지 데이터 변환을 위한 변환 함수들을 정의합니다.
- 학습 데이터셋과 검증 데이터셋에 변환을 적용하여 데이터셋을 생성합니다.
collate_fn함수를 정의하여 배치 단위의 데이터 처리를 수행합니다.- 학습 데이터로더를 생성합니다.
processor = ViTImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
image_mean, image_std = processor.image_mean, processor.image_std
size = processor.size["height"]
normalize = Normalize(mean=image_mean, std=image_std)
train_transforms = Compose([
RandomResizedCrop(size),
RandomApply([ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1)], p=0.5),
ToTensor(),
normalize,
])
val_transforms = Compose([
Resize(size),
CenterCrop(size),
ToTensor(),
normalize,
])
train_ds = CustomDataset(train_dataset, transform=train_transforms)
val_ds = CustomDataset(valid_dataset, transform=val_transforms)
test_dataset = CustomTestDataset("./test(테스트 이미지 데이터 폴더)", transform=val_transforms)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example["label"] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}
train_dataloader = DataLoader(train_ds, collate_fn=collate_fn, batch_size=4)
batch = next(iter(train_dataloader))
for k,v in batch.items():
if isinstance(v, torch.Tensor):
print(k, v.shape)
모델 설정
- ViTForImageClassification 모델을
openai/clip-vit-large-patch14체크포인트로부터 로드합니다. - 모델에 대한 설정과 메트릭을 정의합니다.
from transformers import ViTForImageClassification
model = ViTForImageClassification.from_pretrained('openai/clip-vit-large-patch14',
id2label=id2label,
label2id=label2id)
훈련 및 평가 설정
- 훈련을 위한 인자들을 설정합니다.
- 메트릭 계산을 위한 함수를 정의합니다.
TensorBoard로깅을 위한SummaryWriter를생성합니다.Trainer객체를 생성하여 모델을 훈련하고 검증합니다.- 테스트 데이터셋에 대한 예측을 수행합니다.
metric_name = "accuracy"
args = TrainingArguments(
f"clip_large_14_5",
save_strategy="epoch",
evaluation_strategy="epoch",
learning_rate= 2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=0.5,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model=metric_name,
logging_dir='logs',
remove_unused_columns=False,
)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return dict(accuracy=accuracy_score(predictions, labels))
writer = SummaryWriter('logs')
trainer = Trainer(
model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
data_collator=collate_fn,
compute_metrics=compute_metrics,
tokenizer=processor,
callbacks=[TensorBoardCallback(writer)]
)
trainer.train()
model.save_pretrained('./pt_model1')
예측 결과 분석
- 테스트 데이터셋의 예측 결과를 분석하여 레이블을 추출합니다.
outputs = trainer.predict(test_dataset)
predicted_labels = np.argmax(outputs.predictions, axis=1)
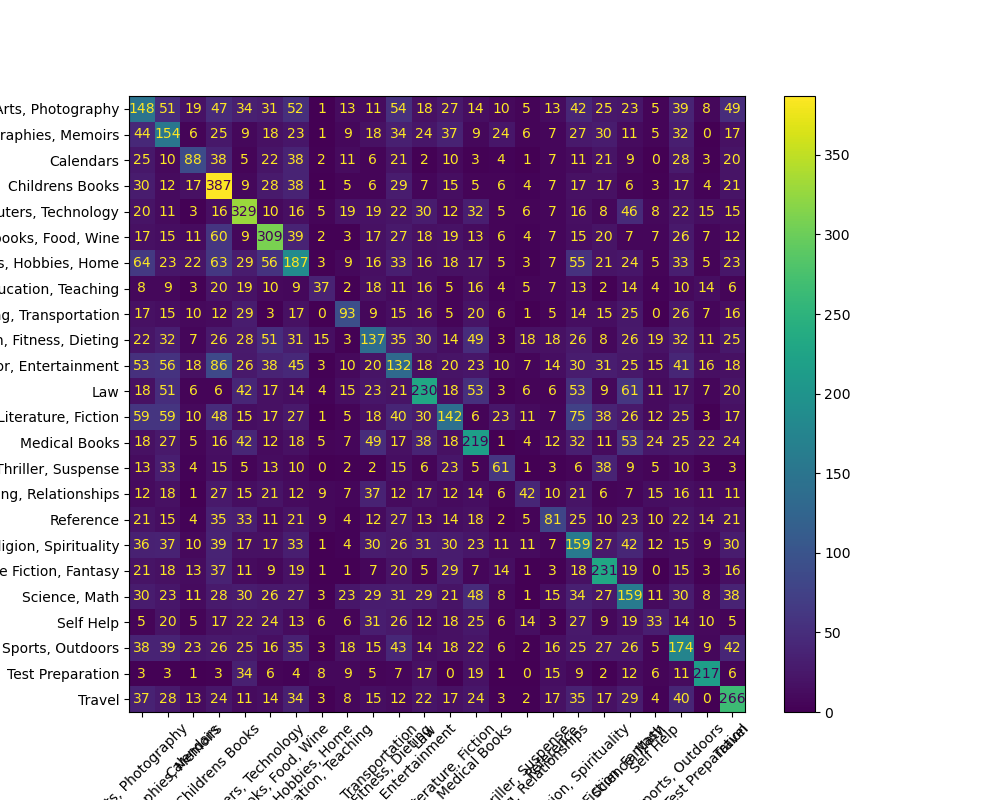
평가 결과 시각화
- 검증 데이터셋에 대한 예측 결과를 분석하여 혼동 행렬을 생성합니다.
- 혼동 행렬을 시각화하여 저장합니다.
outputs = trainer.predict(val_ds)
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
y_true = outputs.label_ids
y_pred = outputs.predictions.argmax(1)
labels = image_datasets.classes
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
fig, ax = plt.subplots(figsize=(10, 8))
disp.plot(xticks_rotation=45, ax=ax)
plt.savefig('confusion_matrix_14_5.png')
writer.close()